
はじめに——「先生がカルテばかり見ている」と感じたことのある方へ
外来で診察を受けながら、「先生、私の顔を見て話を聞いてくれないな」と感じたことはありませんか。
医師がカルテに目を落とすのは、患者さんの話に関心がないからではありません。診察中にその場で書き留めなければ、後で困るからです。私自身、外来で患者さんの話を聞きながら同時にキーボードを打つ時間が、診察時間の半分近くを占めています。
その時間を、患者さんと目を合わせる時間に取り戻すかもしれない技術が、いま世界中の診察室に入り始めました。診察の会話を AI が聞き取り、カルテの下書きまで作ってくれる「アンビエント AI スクライブ」と呼ばれる仕組みです。米国の大手医療システムでは、すでに 1 年で 250 万回以上使われています [15]。
ただし、便利な道具にはいつも影もあります。AI に頼って医師の「素手」のスキルが落ちる現象も、報告され始めました。日本では医師法 17 条が「最終責任は医師」と 1948 年から定めていますが、その線引きが今、改めて問われています。
この記事では、世界の最新エビデンスと日本での選択肢を、現役医師の視点でお伝えします。
アンビエント AI スクライブとは——診察の会話を、AI がカルテにする
「AI に書かせる」ではなく「AI が聞いている」
これまでの医療 AI は、画像診断 AI のように「医師が AI に判定させる」道具でした(その実力の現在地はAI画像診断は医師を超えたか?最新エビデンスで読み解く現在地で詳しく解説しています)。ところが 2024 年以降に急速に広まったのは、まったく別の使い方です。
アンビエント AI スクライブ(環境型 AI 書記)と呼ばれるその仕組みは、診察室の音声を常時聞き取り、医師と患者の会話そのものを、構造化されたカルテの下書きに変えてくれます。医師は会話を終えたあと、AI が作った下書きを 1 分ほどで校正してサインします。診察中のタイピングが、ほとんど消えます。
実際の数字を見てみましょう。米国 Microsoft の Dragon Copilot(旧 Nuance DAX Copilot)は、2024 年時点で 400 を超える医療組織に導入されました。Northwestern Medicine では医師の半数以上が患者対面で使用し、記録時間は 24% 減、夜に自宅で残務を片付ける時間("pajama time" と呼ばれます)は 17% 減ったと報告されています。患者 1 人あたり平均 5 分以上の時間が浮き、医師の 77% が記録品質の改善を実感したそうです。
これを RCT(ランダム化比較試験)で検証したのが、UCLA Health の Lukac らの研究です [1]。238 名の外来医師を Microsoft DAX Copilot 群・Nabla 群・通常ケア群に 1 対 1 対 1 でランダム化した、世界初の本格的な比較試験で、Nabla 群で記録時間の有意な削減と、両 AI 群でバーンアウト・タスク負荷の改善傾向が確認されました。
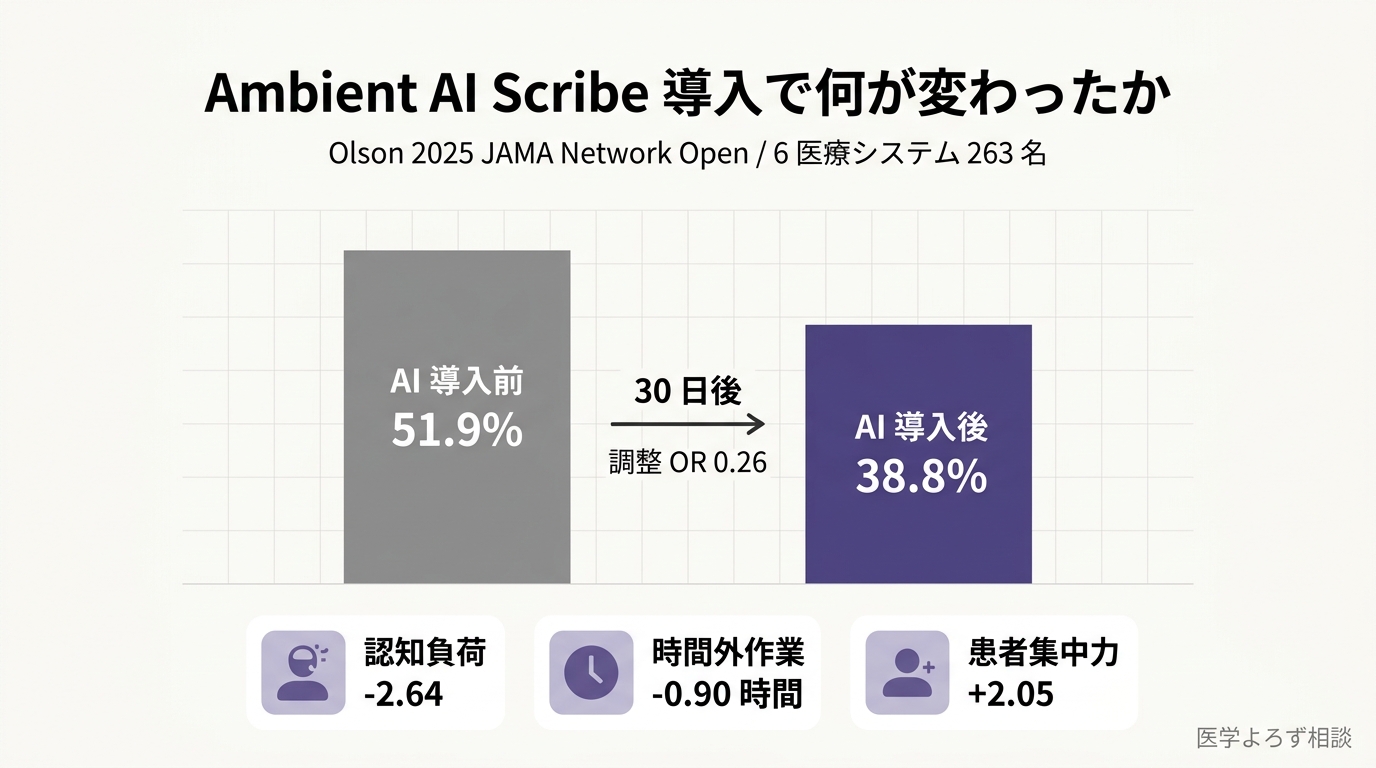
30 日でバーンアウトが 51.9% から 38.8% へ
医師の燃え尽き(バーンアウト)は、日本でも深刻な問題です。2024 年 4 月の医師時間外労働規制が始まり、私の周りでも「夜に書く時間が足りない」「家でカルテを開く生活がつらい」という声が増えています。
アンビエント AI スクライブが、この負担を実際にどれくらい減らせるか——その答えに近づく研究が、2025 年 10 月の JAMA Network Open に掲載されました [2]。Yale New Haven Health を含む 6 つの米国医療システムの 263 名の外来医師・APP(医師業務を分担する診療看護師など)に AI スクライブを導入した前後を比較した研究です。
- バーンアウト率:51.9% → 38.8%(調整オッズ比 0.26、95%信頼区間 0.13-0.54、p<0.001)
- 認知タスク負荷:2.64 ポイント改善
- 診療時間外の記録作業:0.90 時間短縮
- 患者集中力:2.05 ポイント改善
医師の 2 人に 1 人が燃え尽きていた職場が、3 人に 1 人になりました。しかも、わずか 30 日で。著者らは「AI スクライブは行政負担を減らし、臨床医に意味のある職務と専門的ウェルビーイングのための時間をもたらす可能性がある」と結論しています。
ChatGPT のほうが共感的だった——「時間」という変数
アンビエント AI スクライブより前に、世界の医療界に大きな波紋を広げた論文があります。2023 年 6 月、JAMA Internal Medicine に掲載された、UCSD の Ayers らの研究です [4]。
研究チームは、Reddit の医療相談コミュニティに投稿された患者の質問 195 件を選び、本物の医師の回答と、ChatGPT に同じ質問を投げて得た回答を、評価者に盲検で比較させました。結果はこうでした。
- 評価者が好んだ回答:ChatGPT 78.6%、医師 21.4%
- 「品質が良い」以上と判定された割合:ChatGPT が医師の 約 3.6 倍
- 「共感的」以上と判定された割合:ChatGPT が医師の 約 9.8 倍
なぜ AI のほうが共感的に見えたのでしょうか。答えはおそらく「時間」です。AI には次の患者がいません。長く、丁寧に、患者の不安に寄り添って書けます。医師は 5 分の外来で、次の患者が待っています。
Ayers らはこう述べています。「AI アシスタントが医師の患者メッセージ対応をどう改善できるか、探索が必要だ」。実際にその後、Epic(米国最大の電子カルテ)が GPT-4 を患者受信箱(MyChart)に組み込み、Stanford Medicine の 162 名の医師による品質改善研究では、AI が作る下書きの採用率は 20%、医師のバーンアウトや感情的疲労が有意に減ったと報告されています。今では 150 を超える組織で、月 100 万件以上の下書きが生成されています。
中国でも、35,418 件の外来受付会話を対象にした RCT が Nature Medicine に掲載され、看護師と LLM の協働モデルが受付業務の質を高めることが示されました [6]。診察前の「聞き取り・整理・伝達」というインターフェースの部分に、AI が静かに入り込み始めているのです。
便利な道具に潜む影——スキル低下・幻覚・監視
ここまで読むと、AI コパイロットは医師にも患者にも良いことばかりに見えるかもしれません。ただ、最近のエビデンスは、別の側面も同時に映し出しています。
AI に頼ると、医師の「素手」のスキルが落ちる
2025 年 8 月、Lancet Gastroenterology & Hepatology に印象的な観察研究が掲載されました。ポーランドの 4 施設で、AI 内視鏡(大腸ポリープを自動検出する仕組み)を導入した前後で、医師が「AI を使わないとき」のパフォーマンスがどう変わったかを測った、Budzyń らの研究です [8]。
結果は予想を超えていました。AI 内視鏡に習熟した医師たちが AI を切ったとき、ポリープの検出率(ADR)が 28.4% → 22.4%(p=0.0089) と有意に低下していたのです。AI に頼って自分の目で探さなくなった可能性が示唆されました。
「deskilling(脱スキル化)」と呼ばれるこの現象は、車のオートマ化でドライバーのマニュアル運転能力が落ちるのと、構造的には同じです。AI コパイロットは医師の負担を確かに減らしますが、長期的に医師の臨床判断力を少しずつ蝕む可能性があります。この脱スキル化を含む AI 臨床推論の実力と限界は、医療とAI——「ChatGPTに診てもらう」時代は本当に来るのかでさらに詳しく扱っています。
観察研究なので因果関係は確定していません。それでも「AI が使えなくなった日に、医師は素手で患者を救えるか」という問いは、もう避けて通れないと感じます。
AI は、自信たっぷりに嘘をつく
LLM の最も厄介な性質は、自信たっぷりに嘘をつくことです。これを hallucination(幻覚)と呼びます。
2025 年 5 月の npj Digital Medicine で、英国の Tortus AI と Guy's and St Thomas NHS Trust のチームが、医療要約 LLM の幻覚を分類するエラー類型と、臨床安全評価のフレームワークを発表しました [9]。LLM が作る診察要約には「存在しない症状の追加」「指示された薬剤の誤記」「数値の入れ替え」といった、臨床的に致命的なエラーが一定の頻度で混入することを示し、医療機関での導入には系統的な監査が欠かせないと提言しています。
別の SR(JAMA Network Open)では、これまでに発表された 137 件の chatbot 健康助言研究のうち、99.3% が使用した LLM のバージョンを開示しておらず、99.3% がプロンプト設計を記述していないことが判明しました [5]。「AI の医療効果を評価する研究」自体が、再現性のない状態で量産されているのが現状です。
AI が、医師を見張る側に回るとき
NEJM の 2025 年の Perspective は、もうひとつの影に光を当てました。診察中の会話が AI 経由ですべてメタデータ化されれば、保険会社・病院経営・規制当局がそれを使って医師を評価できてしまいます。診察にかかった時間、患者への共感度、ガイドラインからの逸脱率——「医師は定量化された労働者になる」という警告です。
さらに同じ npj Digital Medicine の 2025 年ポリシーブリーフでは、アンビエント AI スクライブの普及で診療報酬請求のコーディング強度が上昇し、保険会社が請求の減額査定で対抗する「コーディング軍拡競争」が始まっていると指摘されました。AI が効率化を生むほど、別の場所に歪みが移っていく構造です。

日本の今——医師法 17 条という枕木
ここまでは世界の話をしてきました。日本ではどうでしょうか。
「最終判断は医師」——2018 年通知の重さ
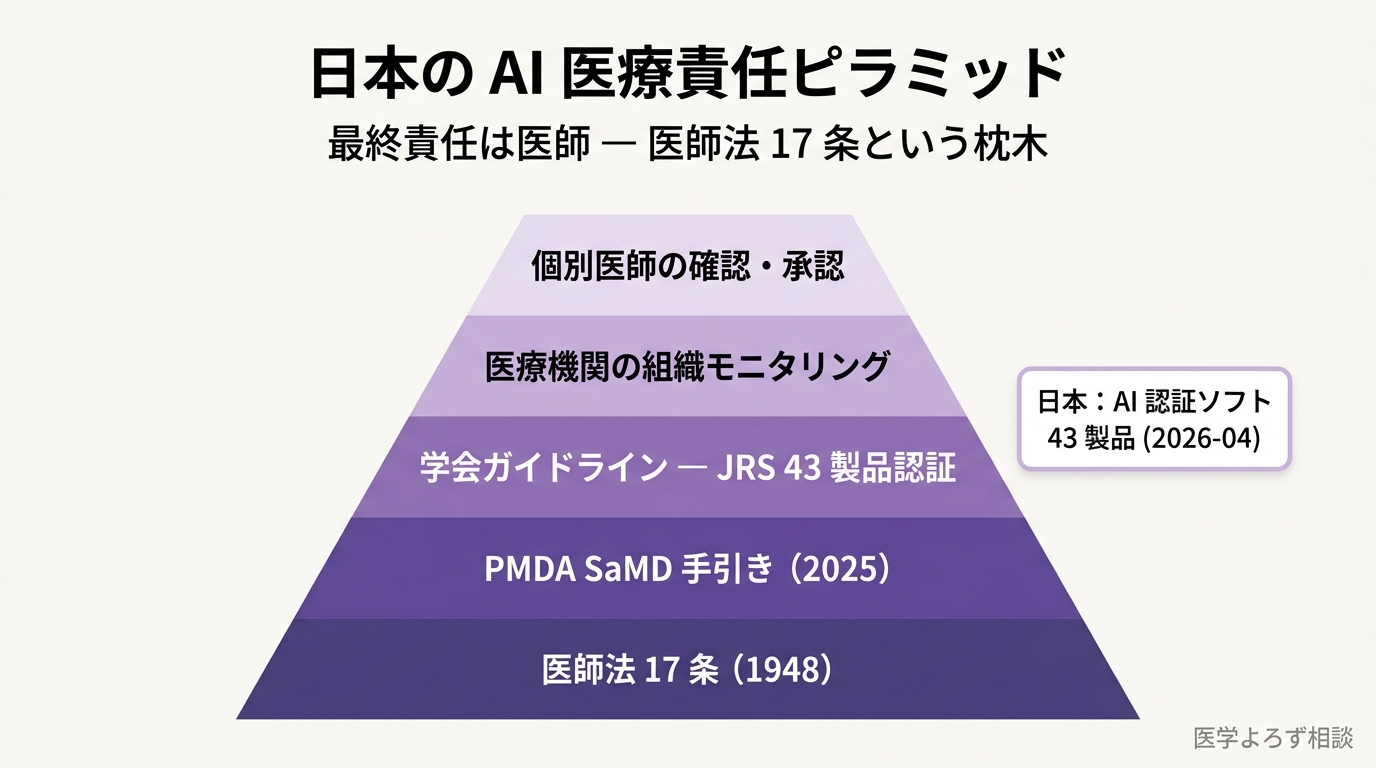
日本には「医師法第 17 条」があります。「医師でなければ医業をなしてはならない」というシンプルな一文ですが、これが医療 AI の議論のすべての出発点になっています。
2018 年 12 月 19 日、厚生労働省は「人工知能を用いた診断、治療等の支援を行うプログラムの利用と医師法第 17 条の規定との関係について」という通知を出しました [13]。要点はこうです。
AI を用いた診断・治療支援プログラムは「医師の判断を支援する補助ツール」と位置付け、最終判断の権限と責任は医師に帰属する。AI が単独で診断・治療判断を下すことは医師法 17 条違反となる。
2026 年現在も、生成 AI も LLM もアンビエント AI スクライブも、すべてこの通知の延長線上で運用されています。「AI が誤った下書きを書いた」も「AI が患者メッセージで誤った回答を作った」も、最終的に承認した医師の責任になります。
これを「制限」と見るか「枕木」と見るかで、医療 AI の景色はずいぶん変わって見えます。私自身は枕木だと感じています。最終責任が医師にあるからこそ、医師は AI を「自分の判断を補強する道具」として使える。逆に責任の所在が曖昧だと、医師は AI を信用できず、患者さんも AI の出力を信用できないからです。
日本医師会 2026 年答申——「何を学ばせ、何を任せず、誰が責任を負うか」
2025 年 2 月に発足した日本医師会「AI の臨床利用に関する検討委員会」は、5 回の審議を経て、2026 年 4 月に答申「AI に関する臨床的課題と生命倫理について」 を発表しました [14]。生産年齢人口減少のなかで AI を医療生産性向上の手段として位置付けつつ、医師に次のことを求めています。
医師は AI に「何を学ばせ、何を任せず、誰が責任を負うか」を明確化する必要がある。
このフレーズは、これからの 10 年の医療 AI 議論を貫く軸になると、私は感じています。「全部 AI に任せる」でも「全部 AI を拒否する」でもなく、任せる範囲を医師職が能動的に決めて、その決定の説明責任を引き受ける——という立場の宣言です。
規制マップ:日本 vs FDA vs EU AI Act
| 国・地域 | 規制枠組み | 状況 |
|---|---|---|
| 日本 | 医師法 17 条(1948)+ PMDA SaMD 手引き(2025 改訂) | AI 認証ソフト 43 製品。最終責任は医師 |
| 米国 | FDA AI/ML SaMD Action Plan + Predetermined Change Control Plan | 1995-2023 年に 690 件超 の機械学習対応医療機器を承認 |
| EU | EU AI Act(2024 年 8 月発効) | 医療目的 AI は ほぼ全て「高リスク」分類。全面適用 2027 年 8 月 |
| WHO | LMM Ethics & Governance Guidance(2024 年 1 月)[15] | 40 以上の勧告、5 領域に分類 |
日本の AI 医療機器承認数は約 60 件と、FDA の 10 分の 1 以下にとどまります。これを「遅れ」と捉えるか「慎重さ」と捉えるかは、見方が分かれるところです。私自身は、医師法 17 条という基礎を持つ日本だからこそ、世界の試行錯誤を後追いで取り入れることで「安全な実装」に到達できる側にいると見ています。
日本で実際に使える AI 医療コパイロット製品(2026 年 5 月時点)
ここからは、「で、日本では今どの製品が使えるのか」という話に入ります。製品ごとに役割もカテゴリーも違いますし、保険適用の有無も違います。中立に並べて、それぞれの輪郭が掴めるようにしました。
カテゴリー別マップ
医師が外来で触れる可能性のある AI コパイロット系製品は、大きく 4 つのカテゴリーに分かれます。
| カテゴリー | 代表的な日本の製品(2026 年 5 月時点) | 役割 |
|---|---|---|
| アンビエント AI スクライブ(診察会話 → カルテ下書き) | medimo AI Clerk、kanaVo、Ubie 生成 AI の音声機能 | 診察会話を聞き取り、カルテ下書きを作る |
| 問診トリアージ AI | ユビー AI 問診(Ubie) | 来院前・受付時の問診を構造化、トリアージ補助 |
| 内視鏡 CADe / CADx | EndoBRAIN シリーズ(オリンパス・サイバネット)、gastroAI-model G/G2(AI Medical Service) | 大腸・胃の内視鏡画像から病変候補を検出・鑑別 |
| 治療用アプリ・医師参照 AI | CureApp HT/SC、HOKUTO AI 機能 | 外来管理アプリ、医師向け臨床支援・論文要約 |
主要 7 製品の比較表
| 製品 | 提供元 | カテゴリー | 日本提供開始 | 主な特徴 | 費用感 | 保険適用 / 承認 |
|---|---|---|---|---|---|---|
| ユビーメディカルナビ(AI 問診 + 生成 AI) | Ubie 株式会社 | 問診トリアージ + 院内業務生成 AI | AI 問診 2017〜、生成 AI 2024-12 β | 問診 AI と RAG・要約・音声を電子カルテと連携 | AI 問診はクリニック向け月額 3 万円〜 | 業務支援 SaaS、保険適用なし。生成 AI は 2026 年 1 月時点で 100 病院(大学病院 10 以上を含む) |
| EndoBRAIN シリーズ(EndoBRAIN-EYE / Plus / X) | サイバネット(開発)/オリンパス(販売) | 内視鏡 CADe / CADx | 2019-03 〜 | 大腸内視鏡の AI 病変検出・鑑別。リアルタイム警告 | 施設導入型、価格は非公表 | PMDA 高度管理医療機器。2024 年 6 月改定で 本邦初の AI 医療機器保険収載(病変検出支援プログラム加算 60 点) |
| gastroAI-model G / G2 | AI Medical Service | 内視鏡 CADe(上部消化管) | 2024-03 〜、G2 は 2025-05 | 早期胃がん特化、生検候補を矩形表示 | 施設導入型、価格非公開 | PMDA 製造販売承認(2023-12)。保険収載はまだ |
| CureApp HT / SC ほか | CureApp | 治療用アプリ(SaMD) | SC 2020-12、HT 2022-09、減酒 2025-02 | 医師が処方し患者がアプリで自己管理。経過は医師画面で確認 | HT は患者 3 割負担で月約 2,490 円、初回から 6 か月 | PMDA 承認 SaMD。HT は新規技術料、SC は B100 準用で算定 |
| medimo AI Clerk | medimo(スズケングループ) | アンビエント AI スクライブ | 2022 〜 | Whisper ベース医療特化音声認識、約 5 秒で SOAP 草案 | 月額 19,800 円(税込)〜、初期 15 万円 | 業務支援 SaaS、保険適用なし。2026 年 2 月時点で全国 1,000 施設超、累計 100 万件超 |
| kanaVo | kanata 株式会社 | アンビエント AI スクライブ | β版 2021〜、製品版提供中 | 医師・患者の声を分離認識、早口・マスク越し対応(公称 約 95%) | 月額 25,000 円〜、毎月 5 時間まで無料 | 業務支援 SaaS、保険適用なし。外来・在宅・オンラインに対応 |
| HOKUTO AI 機能 | 株式会社 HOKUTO | 医師向け臨床支援 AI(説明文生成・論文要約) | アプリ 2019〜、AI は 2023-04 試験導入 | GPT-4 で患者向け説明文・論文の日本語要約。UpToDate・PubMed 横断検索 | 完全無料 | 医療機器ではなく医師向けアプリ。日本の医師の約 3 人に 1 人が利用と公表 |
海外の参照点(2026 年 5 月時点で日本未展開)
| 製品 | 提供元 | 状況 |
|---|---|---|
| Microsoft Dragon Copilot(旧 Nuance DAX Copilot + Dragon Medical One) | Microsoft | 米・加・英・愛・仏・独・墺・蘭・白の 9 か国+ 58 言語に拡大中。日本ロールアウトは未発表。全世界で約 10 万人超の臨床医が利用 |
| Abridge | Abridge AI, Inc. | 米国 250 ヘルスシステムで年 8,000 万件超の診察に利用、評価額 50 億ドル超。Epic と深く統合。日本展開の公式発表なし |
製品ごとの簡潔な紹介
ユビー(Ubie)
日本最大級の医療機関向け生成 AI プラットフォームです。AI 問診と生成 AI(要約・検索・音声・画像)を一体で提供し、全診療科のクリニックから大学病院までカバーしています。2026 年 1 月時点で大学病院 10 施設以上を含む 100 病院に生成 AI を導入していると公表されています。
EndoBRAIN シリーズ(オリンパス・サイバネット)
日本の AI 医療機器の歴史的代表選手です。2019 年に本邦初の AI 内視鏡として薬事承認され、2024 年 6 月改定で AI 医療機器として日本で初めて保険収載されました(病変検出支援プログラム加算 60 点)。大腸内視鏡を実施する消化器内科向けです。
gastroAI-model G / G2(AI Medical Service)
早期胃がんに特化した、国内唯一の上部消化管 AI 内視鏡です。2023 年 12 月に PMDA 承認、2024 年 3 月に発売、2025 年 5 月に G2 が発売されました。保険収載はこれからの段階ですが、世界に先行する日本の内視鏡 AI 領域で EndoBRAIN と並ぶ代表選手です。
CureApp
日本の治療用アプリ(SaMD)の最大手で、ニコチン依存症(2020)・高血圧(2022)・減酒(2025)・小児 ADHD などを順次承認・上市しています。HT(高血圧)は患者 3 割負担で月約 2,490 円・初回から 6 か月限度、SC(ニコチン依存症)は B100 を準用した指導管理加算で算定されます。帝人ファーマと共同販売で全国に展開しています。
medimo AI Clerk(スズケングループ)
国内のクリニック向けアンビエント AI スクライブの代表格です。Whisper ベースの医療特化音声認識で、診察会話を約 5 秒で SOAP 草案にしてくれます。月額 19,800 円(税込)と中小医療機関でも導入可能な価格帯で、2026 年 2 月時点で全国 1,000 施設超・累計 100 万件超の診察で使われています。2025 年にスズケンが子会社化し、全国流通網に乗せました。
kanaVo(kanata 株式会社)
月額 25,000 円〜、毎月 5 時間まで無料という気軽な価格設計のアンビエント AI スクライブです。外来・在宅・オンライン診療まで横断対応で、医師・患者の声を分離認識する点や、早口・マスク越しでも 約 95% の認識率を公称しているのが特徴です。
HOKUTO
「日本の医師の 3 人に 1 人」が使う医師向け臨床支援アプリで、2023 年 4 月から GPT-4 ベースの患者向け説明文生成と論文の日本語要約機能を提供しています。カルテそのものを書くタイプではなく、医師の意思決定・患者説明・文献探索を補助する「軽量コパイロット」というポジションです。完全無料なので、外来のすき間時間に試しやすい選択肢でもあります。
表を眺めて見えてくること
5 つほど補足しておきます。
- 製品の役割は層が違う——アンビエント AI スクライブ(medimo / kanaVo / Ubie 生成 AI 音声)、問診トリアージ(Ubie AI 問診)、内視鏡 CAD(EndoBRAIN / gastroAI)、治療用アプリ(CureApp)、医師参照 AI(HOKUTO)は、解く課題が違います。「どれが優れているか」ではなく「どこの課題を解きたいか」で選ぶ前提です。
- 保険適用の有無——EndoBRAIN-EYE(2024 年 6 月の本邦初 AI 医療機器保険収載)と CureApp HT/SC は保険の中で稼げる仕組みですが、アンビエント AI スクライブ系(medimo / kanaVo / Ubie 生成 AI / HOKUTO)はすべて業務支援 SaaS で保険適用なしです。経営側にとってはここが大きな分岐点になります。
- 海外大手は日本未展開——Microsoft Dragon Copilot と Abridge は 2026 年 5 月時点で日本ロールアウトの公式アナウンスがありません。日本のアンビエント AI スクライブ選択肢は、当面は国内勢で構成されることになります。
- 「医療機器」と「業務支援 SaaS」は規制が違う——EndoBRAIN・gastroAI・CureApp は PMDA 承認の医療機器(SaMD)、ほかは業務支援 SaaS。承認のハードルも、責任の所在も変わってきます。
- 公平に並べているだけ——どの製品が「最高」とは書きません。提供開始時期、対象、費用、保険適用の有無を同じ深さで並べていますので、ご自身の目的に合わせて見比べてください。
最後に、日本ではまだアンビエント AI スクライブを対象にした大規模なピボタル試験は行われていません(2026 年 5 月時点)。岡山大学病院の山本らが、医学生の問診技術向上を AI 模擬患者で検証した非ランダム化比較研究 [11] が、日本発の数少ない臨床エビデンスです。世界の RCT を読み解きつつ、日本独自のデータをこれから積み上げる段階にあります。
患者として、診察室で AI が同席する時に知っておきたいこと
ここからは、患者として外来に行ったときに知っておいてほしい話を書きます。
「AI が同席します」と言われたら——確認したい 3 つのこと
アンビエント AI スクライブを使う医療機関はこれから増えていきます。診察前に「AI が会話を録音してカルテの下書きを作りますが、よろしいですか」と確認される場面も出てくるでしょう。そのとき気にしていただきたいのは、次の 3 点です。
- 録音データの保存と削除のルール——どこに、いつまで保存されるのか。診察後に削除を申し出られるか
- AI 出力を医師がチェックする工程の有無——「AI の下書きをそのまま使う」のか「医師がカルテとして整える」のか
- 拒否しても診療に支障がないこと——AI 同席の同意は本来、完全に任意のはずです
これは特別に新しい同意ではありません。診察室の録音や、医学生の同席についても、似た仕組みがすでにあります。AI への参加に拒否権を持つことは、患者さんの正当な権利です。
AI が書いた紹介状や説明書を読むコツ
紹介状や検査結果の説明書を AI が下書きする時代も、もう始まっています。読むときのコツが一つだけあります。「数字が具体的か」を見てください。
たとえば「中等度の脂肪肝です」よりも「FibroScan 8.5 kPa、軽度から中等度の線維化(F1-F2)が疑われます」のほうが、医師が AI の下書きをきちんと校閲した可能性が高くなります。逆に抽象的な表現ばかり並んでいる場合は、医師があまり手を入れずにサインした可能性もあります——そのときは遠慮なく「これはどういう意味ですか」と聞いてみてください。
JAMA Network Open に掲載された 43 か国 13,806 人の患者を対象にした多国横断研究 [10] では、患者の 72.9% が「医師主導の意思決定」を希望し、70.2% が「説明可能な AI」を求めたことがわかっています。AI が診療に入ることへの治療成果の正確性への信頼は 41.8% にとどまります。患者さんは AI を拒否しているわけではなく、「医師が責任を持って使う AI」を望んでいるのです。
科学の現在地:わかっていること、まだわからないこと
わかっていること:
- アンビエント AI スクライブは、医師のバーンアウトを統計的に有意に減らせる [2]
- 患者向け AI チャットボットは、ときに医師よりも共感的に応答できる [4]
- 大規模医療システムでは、月 100 万回規模の AI 利用がすでに日常化している [16]
まだわからないこと:
- 10 年使い続けたとき、医師の臨床判断力に何が起きるのか
- AI が関与した医療事故の法的責任の境界線(日本での確定判例はまだありません)
- 日本人医師・日本人患者に、欧米のデータがそのまま当てはまるかどうか
これから出てくるであろう答え:
- 日本の大学病院で計画されている複数の RCT
- EU AI Act の本格適用後の規制実例(2027 年 8 月以降)
- 長期の脱スキル化(deskilling)のメカニズム解明
おわりに——AI は医師の代わりではなく、医師の余裕を取り戻す道具
世界では今、診察室で月 250 万回、AI が医師の隣に座っています。日本の医師法 17 条は「最終責任は医師」と明確に定めていて、これは AI 普及のブレーキではなく、AI を安全に育てるための枕木です。
患者さんとして知っておいていただきたいのは、AI は医師の代わりではなく、医師の「余裕と共感」を取り戻すための道具だということ。そして、その余裕を何に使うかは、医師の選択次第だということです。
私自身、医療 AI コンサルティングの現場で経営層と話していると、「AI を入れれば全部解決する」という幻想と、「AI を入れれば医師が要らなくなる」という別の幻想の両方に出会います。どちらも違うと思います。AI は医師の良心を増幅する道具であって、置き換える道具ではありません。診察室で医師があなたの目をしっかり見ているなら、その背景で AI が裏方として働いている可能性は、これからどんどん高まっていきます。
もしあなたの主治医がまだ AI を使っていなくても、それは「遅れている」のではなく、「責任の重さを慎重に検討している」ということでもあります。日本医師会の 2026 年の答申はこう言いました——医師は「何を学ばせ、何を任せず、誰が責任を負うか」を明確化する責任を負う、と [14]。
AI が同席する診察室の物語は、まだ始まったばかりです。次の外来でカルテばかり見ている主治医に会ったら、「先生、AI スクライブ試してみたら?」と、雑談がてら聞いてみてもいいかもしれません。