
はじめに:「とりあえずChatGPTに聞いてみよう」の時代
深夜2時、子どもが突然の高熱。救急に電話する前に、スマートフォンを手に取り「ChatGPT 子ども 39度 対処法」と入力する。
このような行動が、もはや珍しくなくなりました。2025年の時点で、大規模言語モデル(LLM: Large Language Model — 大量のテキストデータで学習したAI)であるChatGPTの月間アクティブユーザーは数億人規模に達し、医療相談は最も頻繁な利用目的の一つです。Google検索の代わりにAIチャットボットへ症状を打ち込む人が急増しています。
では、このAIの「医学力」は実際どの程度なのでしょうか。
答えは、想像以上に複雑です。ChatGPTは米国医師国家試験(USMLE: United States Medical Licensing Examination)で正答率95%を叩き出す一方 [1]、実際の臨床を模擬した環境では精度が元の10分の1以下に急落します [2]。この「試験の秀才が外来で落第する」という現象は、AI医療の本質を理解するうえで避けて通れない事実です。
本記事では、2024年から2026年にかけて発表された最新の研究群を横断的にレビューし、AIの臨床推論力の「本当の実力」と「まだ超えられない壁」を、臨床医の視点から解き明かしていきます。
AIは試験に受かるが、外来では落第する
医師国家試験で95%——しかし話はそこで終わらない
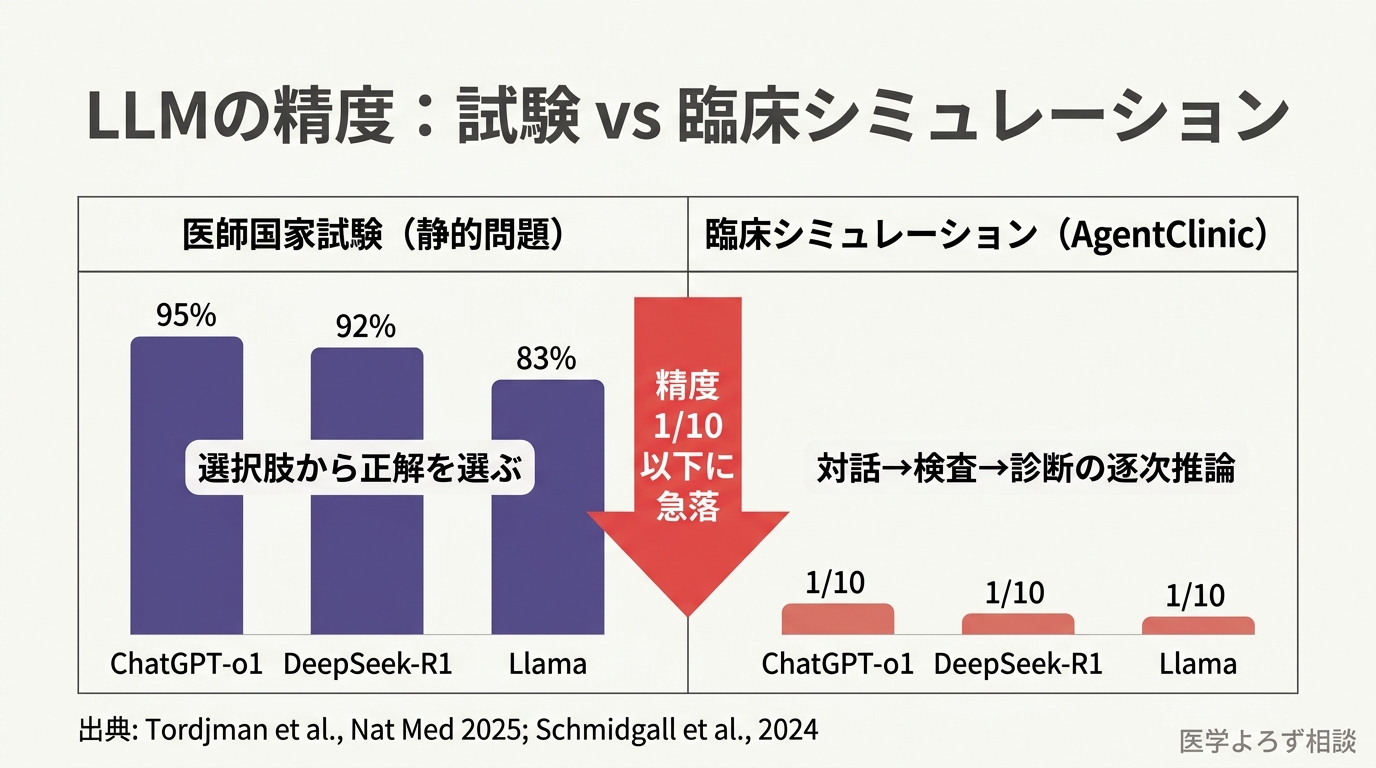
2025年、Nature MedicineにDeepSeek-R1、ChatGPT-o1、Llama 3.1-405Bという3つの主要LLMを医学タスクで比較したベンチマーク研究が掲載されました [1]。結果は華々しいものでした。
- ChatGPT-o1: USMLE正答率 95%
- DeepSeek-R1: 正答率 92%
- Llama 3.1-405B: 正答率 83%
しかし同じ研究で、テキストベースの臨床症例(実際の患者の病歴から診断する課題)に移ると、成績は劇的に変わりました。ChatGPT-o1で55%、DeepSeek-R1で57%。USMLEの華々しい成績の半分程度にまで低下したのです。
この結果は何を意味するのでしょうか。USMLEは「選択肢から正解を選ぶ」試験です。一方、実際の臨床は「何を聞くべきか」「どの検査を出すべきか」を自ら考える作業です。AIは前者が得意で、後者が苦手だということです。
AgentClinic:精度が10分の1に落ちる衝撃
この「試験と外来のギャップ」を定量化した画期的な研究が、AgentClinic(エージェントクリニック)です [2]。
AgentClinicは、LLMが「医師役」として模擬患者と対話し、検査を指示し、診断にたどり着くまでの全プロセスをシミュレーションするベンチマークです。9つの専門領域、7つの言語に対応し、MedQA(米国医師国家試験の問題集)、MIMIC-IV(大規模患者データベース)、NEJM Case Challenge(ニューイングランド医学誌の症例問題)から構築されています。
衝撃的だったのは、MedQAの選択問題で高得点を取るモデルが、AgentClinicの逐次的な臨床推論環境に置かれると、診断精度が元の10分の1以下に急落したという結果です。さらにバイアス(先入観)を導入すると、精度はさらに低下し、模擬患者の治療遵守度や再受診意欲も下がりました。
21モデルを並べてわかった「鑑別診断の壁」
2026年4月、JAMA Network Openに掲載されたハーバード大学の研究は、GPT-5、Claude 4.5 Opus、Gemini 3.0、Grok 4など最新の21モデルを、臨床推論の各段階で評価しました [3]。
評価指標としてPrIME-LLM(プライム・エルエルエム: LLMの医学的評価のための比例指標)を用い、29の臨床ビネット(模擬症例)で計16,254回の回答を分析した結果、興味深いパターンが浮かび上がりました。
| 臨床推論の段階 | パフォーマンス | 失敗率 |
|---|---|---|
| 最終診断 | 高い | 0.09〜0.39 |
| 検査指示 | 高い | — |
| 鑑別診断 | 低い | 0.90〜1.00 |
| 治療方針 | 中程度 | — |
注目すべきは鑑別診断の失敗率が全モデルで0.80を超えた点です。つまり、最終的な「答え」は当てられても、「この症状はA、B、Cのどれかもしれない」という臨床的に最も重要な思考プロセスでは、ほぼ全てのモデルが苦戦したのです。
臨床の現場では、最初から「答え」がわかることはありません。患者の訴えから複数の可能性を挙げ、一つずつ絞り込んでいくのが臨床推論の核心です。AIがこの最初のステップで躓くということは、現時点では「安全な主治医」として機能するには程遠いことを意味します。
なぜAIは「柔軟な推論」ができないのか
スタンフォード大学とUCSFの研究チームは、この弱点の根本原因を探りました [4]。彼らが開発したmARC-QA(マーク・キューエー: 医学的抽象・推論コーパス)は、アインシュテルング効果(Einstellung Effect — 過去の経験に固執して柔軟な思考ができなくなる現象)をAIに意図的に誘発するテストです。
結果、o1、Gemini、Claude、DeepSeekといった最先端モデルが、医師と比較して著しく劣るパフォーマンスを示しました。LLMは訓練データのパターンマッチングに過度に依存し、「常識的な医学推論」が欠如していたのです。さらに深刻なのは、不正確な回答に対しても高い確信度を示す「過信」傾向が全モデルで見られたことです。
これは患者にとって最も危険なシナリオです。「わかりません」と言わないAI、自信満々に間違えるAI。臨床医が日常的に抱く「この患者は何か違う」という直感的な不安——それはAIにはまだ備わっていないのです。
AI模擬患者が医学教育を変えつつある
AIPatient:精度94%で人間の模擬患者に匹敵
AIが「医師役」として限界を示す一方で、「患者役」としては著しい成果を上げています。
香港中文大学とハーバード大学を中心とする国際チームが開発したAIPatient(エーアイペイシェント)は、LLMベースの6つの専門エージェントと実患者データ(MIMIC-III)を組み合わせた模擬患者システムです [5]。
このシステムの特筆すべき成果は以下の通りです。
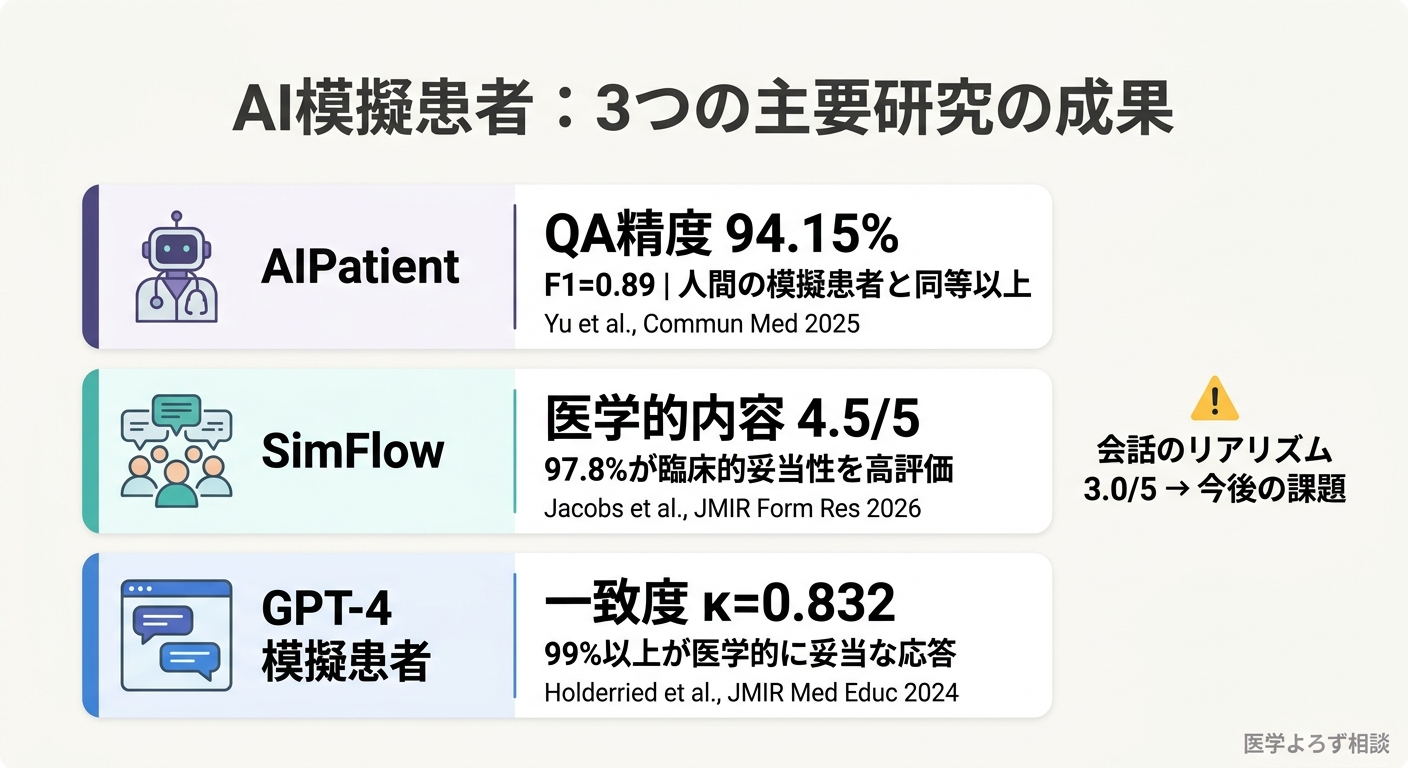
- 質問応答精度: 94.15%(6エージェント全稼働時)
- 知識ベースの妥当性: F1スコア=0.89
- 可読性: Flesch Reading Ease 68.77(医療専門家全般がアクセス可能なレベル)
- 安定性: ANOVA F値=0.6126(p>0.1)で有意なばらつきなし
医学生を対象としたユーザー試験では、問診トレーニングにおいて人間の模擬患者と同等以上の忠実度と教育的価値が確認されました。
SimFlow:英国3校での実証研究
2026年3月、JMIR Formative Researchに掲載された多施設横断研究では、SimFlowというAI模擬患者システムが英国の医学部で評価されました [6]。
47名の医学生・一般開業医(GP: General Practitioner)が参加した結果を見てみましょう。
| 評価項目 | 中央値(5点満点) | 特筆事項 |
|---|---|---|
| 医学的内容 | 4.5 | 97.8%が臨床的妥当性を高評価 |
| 教育的価値 | 4.0 | 反復練習を促進 |
| 会話のリアリズム | 3.0 | 改善の余地あり |
「内容は正確だが会話が不自然」——この評価は、現在のAI模擬患者の限界を端的に表しています。医学的知識は十分でも、患者が見せる微妙な表情の変化、言い澱み、沈黙の意味を再現するには至っていません。
テュービンゲン大学:GPT-4と人間評価者の一致率κ=0.832
ドイツのテュービンゲン大学で行われた前向き研究では、GPT-4を模擬患者兼フィードバック生成器として106名の医学部3年生に使用しました [7]。1,894の質問・応答ペアを分析した結果、GPT-4のロールプレイ応答は99%以上で医学的に妥当と判定されました。
人間の評価者とのフィードバック一致度はCohen κ=0.832(「ほぼ完全な一致」に分類される水準)。ただし45のフィードバックカテゴリのうち8つではκ<0.6と、過度に具体的なフィードバックや人間の判断と乖離するケースも確認されました。
これらの研究が示しているのは、AIは「教える側」としては限界があるが、「学ぶ相手」としては非常に優秀だということです。医学生が深夜に何度でも問診練習できる環境を低コストで提供できる——これは医学教育における静かな革命です。
「精度98%」の真実——AI研究の見方を変える
なぜ「精度」の数字を額面通りに受け取れないのか
「AI画像診断の精度98%」——このような見出しを見たとき、あなたはどう感じるでしょうか。「もう医者はいらないのでは」と思う方もいるかもしれません。しかし、この数字の裏側を知ることが重要です。
2025年、Nature Medicineに掲載されたSTARD-AI(スタードAI: AI診断精度研究の報告基準)ガイドラインは、240名以上の国際専門家が策定したAI診断研究の報告基準です [8]。このガイドラインが策定された背景には、既存のAI診断研究に深刻な方法論的問題があるという認識がありました。
STARD-AIが指摘する主な問題点は以下の通りです。
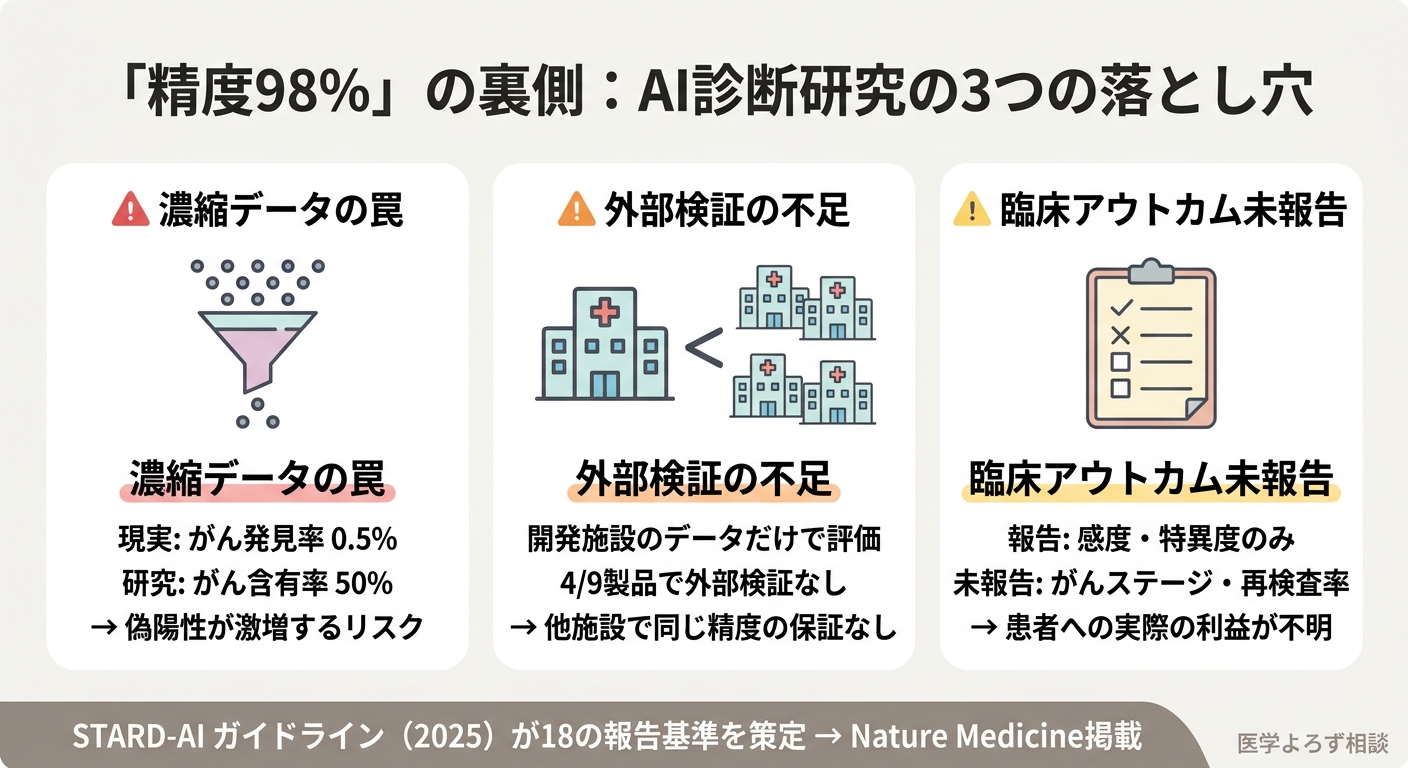
データの偏り: AI研究の多くは「濃縮データセット」(病気の人を意図的に多く含めたデータ)で評価されています。現実の医療では、検査を受ける人の大半は健康です。例えば乳がん検診では、受診者のうちがんが見つかるのはわずか0.5%前後。「病気の人50%、健康な人50%」のデータで99%の精度を達成しても、実際の検診環境では偽陽性(がんでないのにがんと判定される)が激増する可能性があります。
外部検証の不足: 開発に使ったデータと同じ施設のデータで評価する「内部検証」だけでは、他の施設で同じ精度が出る保証はありません。STARD-AIは18の新規・修正項目を策定し、データセットの記述、AI評価方法、アルゴリズムのバイアスと公平性への配慮を求めています。
FDA承認1,451件の光と影
米国食品医薬品局(FDA: Food and Drug Administration)が認可したAI医療機器は、2025年12月時点で累計1,451件に達しています [9]。2025年単年で295件と過去最多を記録し、その76%が放射線科領域に集中しています。
しかし、イェール大学の研究チームがFDA承認済みAI乳がんスクリーニング製品9件を詳細に分析したところ、深刻な問題が浮かび上がりました [10]。
- 全製品が後方視的データ(過去の検査結果)のみで承認された
- 7製品が濃縮データを使用していた
- 4製品で外部検証の詳細が不足していた
- 臨床的に意味のあるアウトカム(がんのステージ、再検査率など)の報告はゼロ
「FDA承認」は安全性と有効性の保証のように聞こえますが、現行の承認基準では、実際の臨床現場での有用性を十分に評価できていないのが実情です。
30研究・4,762症例のメタアナリシスが示す現在地
では、LLMの診断能力は全体としてどの程度なのでしょうか。2025年のシステマティックレビュー/メタアナリシス(SR/MA: 複数の研究を統合的に分析する最もエビデンスレベルの高い研究手法)は、19種のLLMを対象に30研究、4,762症例を分析しました [11]。
結果は、LLMの可能性と限界の両方を明確に示すものでした。
- 一次診断精度: 25%〜97.8%(モデルと領域で大きなばらつき)
- トリアージ精度: 66.5%〜98%
- 臨床専門家との比較: 全体としてまだ及ばない
「25%〜97.8%」という幅の広さ自体が、AIの現状を物語っています。得意な領域(典型的な皮膚疾患の画像分類など)では高い精度を発揮する一方、複雑な臨床推論が求められる場面では精度が大幅に低下するのです。
AI×医師のハイブリッド——コパイロットモデルの可能性
「AIが下書き、医師が判断」の効果
AIが単独で診断を下すのではなく、医師の判断を補助する「コパイロット」(副操縦士)モデル。このアプローチの有効性を示す興味深い研究が報告されています。
223名の医師・看護師が参加した介入研究では、AIの推奨が正しい場合、参加者の正答率は10倍に向上しました(オッズ比: OR=10.0, p<0.001)[12]。ORとは「オッズ比」のことで、ある条件下での結果の起こりやすさを比較する指標です。10.0は「AI推奨ありの場合、正解する確率が10倍高い」ことを意味します。
しかし、この研究は同時にAIの影の側面も明らかにしました。AIの推奨が誤っていた場合、参加者の精度は同等に低下したのです。高い基礎診断能力(OR=2.44)、関連する専門資格(OR=1.40)、長い臨床経験(OR=1.89)は診断精度と関連していましたが、AIの正誤の影響はこれらの人的要因よりもはるかに大きかったのです。
これは何を意味するでしょうか。AIが正しいときは最高の助手になりますが、間違うときは最悪の助言者になる。そして、経験豊富な医師でさえ、AIの誤った推奨に引きずられるリスクがあるということです。
救急医療での活用可能性
スタンフォード大学のスコーピングレビューは、救急医療におけるLLM活用の全体像を俯瞰しました [13]。2018年から2023年の43研究を分析し、4つの主要テーマを特定しています。
- 臨床判断支援: リアルタイムのトリアージ支援。緊急度判定の補助
- ワークフロー効率化: 診療録の自動要約で事務作業を削減
- リスク・倫理・透明性: 出力の信頼性と説明可能性の課題
- 教育・コミュニケーション: 医療者のトレーニング支援
特に有望なのは「ワークフロー効率化」です。救急医が患者対応と書類作成に追われる状況で、AIが診療録の下書きを作成し、医師がそれを確認・修正するモデルは、医師の負担軽減に直結します。
認知的脱スキル化——AI依存がもたらす最大の懸念
大腸内視鏡で「初の実証」
2025年8月、Lancet Gastroenterology & Hepatologyに掲載された研究は、AI医療の議論に根本的な問題を投じました [14]。
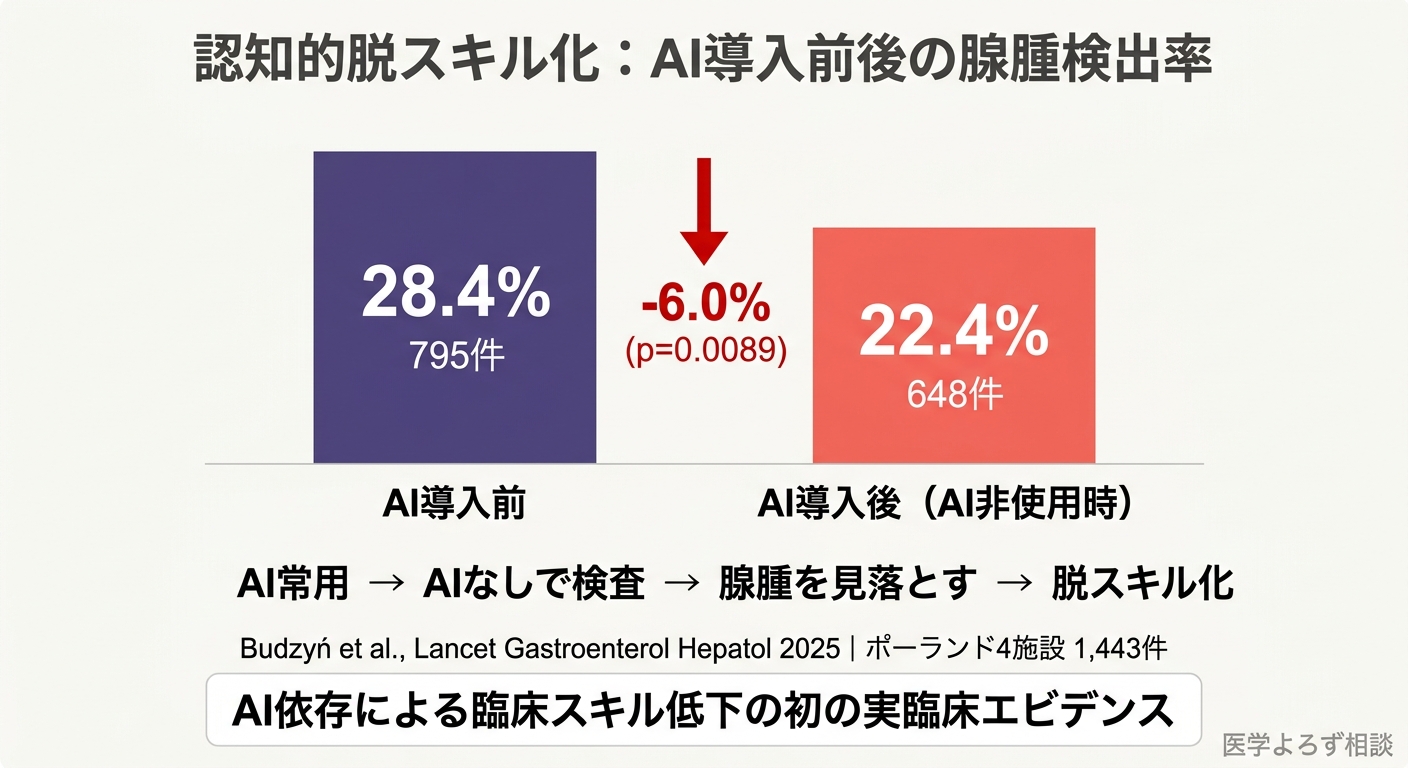
ポーランドの4施設で行われたACCEPT試験の付随研究で、AIポリープ検出ツールを導入した後の内視鏡医の行動変化を調べたものです。AI導入前後で、AI非使用時(AIを使わない通常の大腸内視鏡)の腺腫検出率(ADR: Adenoma Detection Rate — 大腸がんの前段階である腺腫を見つける割合)を比較しました。
結果は衝撃的でした。
- AI導入前のADR: 28.4%(795件)
- AI導入後のADR: 22.4%(648件)
- 絶対差: -6.0%(95%CI: -10.5〜-1.6, p=0.0089)
つまり、AIを日常的に使うようになった内視鏡医が、AIなしで検査を行うと、以前より腺腫を見落とすようになったのです。多変量解析でも、AI暴露(OR=0.69)は患者の性別(OR=1.78)や年齢(OR=3.60)と並んで、ADRの独立した予測因子でした。
これは認知的脱スキル化(deskilling)——自動化への依存により、人間の認知的スキルが退化する現象——の医療における初の実臨床エビデンスです。
なぜ脳は「怠ける」のか
AIへの認知的依存には、神経生物学的な根拠があります。認知タスクを繰り返し外部ツールに委ねると、以下のような神経適応が起こることが報告されています。
- 前頭前皮質の活動低下: 臨床タスク中の能動的推論が減少
- 海馬の関与減少: 独立した学習と記憶形成の弱化
- ドーパミン報酬系: 外部支援による「楽な」戦略が強化される
特に脆弱なのは初期研修医です。臨床スキルの学習・定着段階にある若い医師が、最初からAIに依存する環境で育つと、独立した臨床推論力が十分に発達しないリスクがあります。
メンタルヘルス領域の限界
生成AIのメンタルヘルス領域での能力を評価したシステマティックレビューも、AIの限界を鮮明にしています [15]。ChatGPT-3.5/4.0、Bard、Claudeを評価した8研究の分析で、AIは心理教育や感情認識では一定の能力を示しましたが、診断精度、文化的適切性、感情的関与には明確な限界がありました。
ユーザーからは「信頼性への懸念」「正確性への不安」「感情的関与の欠如」が繰り返し報告されています。つまり、患者が最も必要とする「寄り添い」の部分で、AIは最も力を発揮できないのです。
日本の読者へ:AI医療の「今」と付き合い方
日本のAI医療機器承認の現状
日本の医薬品医療機器総合機構(PMDA: Pharmaceuticals and Medical Devices Agency)も、AI医療機器の承認を進めています。特に内視鏡領域では、EndoBRAIN(エンドブレイン)シリーズが先駆的な役割を果たし、大腸ポリープの画像診断支援AIとして複数製品が承認されています。
国立がん研究センターとNECが共同開発したWISE VISION内視鏡画像解析AIは、1万病変以上の内視鏡画像で学習し、独立したテストデータで98%以上の病変検出率を達成しています。ただし、先述のSTARD-AIガイドラインが指摘するように、こうした数値の解釈には慎重さが求められます。
AIヘルスケアアプリを使う際の5つのチェックポイント
市販のAIヘルスケアアプリやChatGPTを医療相談に使う際、以下の点を確認してください。
- 緊急症状はAIに聞かない: 胸痛、呼吸困難、意識障害、大量出血など緊急性の高い症状は、迷わず119番か救急外来へ
- 「AIの回答=診断」ではない: AIの出力はあくまで「情報提供」であり、「医師の診断」ではありません。日本の法律上、診断行為は医師にしか認められていません
- 出典を確認する: AIが「研究によると」と言った場合、その研究が実在するか確認してください。LLMは存在しない論文を自信満々に引用すること(ハルシネーション)があります
- 個人情報の入力に注意: 病歴や検査結果をAIチャットに入力する際は、そのデータがどう処理されるかを確認しましょう
- セカンドオピニオンの代替にはならない: AIの回答に安心して受診しないのは危険です。気になる症状があれば、かかりつけ医に相談してください
受診の判断基準
AIに相談するのが適切な場面と、医師に直接相談すべき場面を整理しておきましょう。
| AIに聞いてよい場面 | 医師に相談すべき場面 |
|---|---|
| 一般的な健康情報の収集 | 具体的な症状の診断 |
| 薬の一般的な情報確認 | 薬の変更・中止の判断 |
| 検査結果の用語の意味 | 検査結果の解釈と対応 |
| 受診前の準備情報 | 治療方針の決定 |
| 生活習慣の一般的なアドバイス | 精神的な不調・危機的状況 |
科学の現在地:わかっていること、いないこと
確立された知見:
- LLMは医師国家試験レベルの静的問題で人間の医師に匹敵する精度を持つ [1][3]
- 逐次的な臨床推論(対話型問診→鑑別診断→検査→確定診断)では精度が大幅に低下する [2][3]
- AI模擬患者は医学教育において人間の模擬患者に匹敵する教育効果を持つ [5][6][7]
- AI補助への継続的な暴露は、非AI環境での臨床パフォーマンスを低下させうる [14]
- 誤ったAI推奨は、医療者の診断精度を有意に低下させる [12]
未解明点・限界:
- 鑑別診断の精度向上に必要なLLMアーキテクチャの改良方向
- 認知的脱スキル化を防止しながらAIを臨床導入する最適なプロトコル
- 日本語での臨床推論精度(多くの研究は英語中心)
- 長期的な患者アウトカムへのAI補助の影響(大規模RCTの不足)
- AIの誤りを医師が適切に検出できる条件と限界
おわりに:AIは最高の勉強仲間だが、まだ信頼できる主治医ではない
この記事を書きながら、私自身もChatGPTに何度か質問をしました。最新論文の要約を頼み、統計手法の確認に使い、英語論文の日本語要約を依頼しました。AIは確かに優秀な「研究助手」です。
しかし、外来で患者さんと向き合うとき、AIの出力をそのまま使うことは決してありません。
患者さんの顔色、声のトーン、言い澱み、「大丈夫です」と言いながら目が不安を訴えている様子——臨床推論とは、こうした言語化できない情報を統合する作業です。LLMが処理できるのは「テキスト化された情報」だけ。そこに、現時点での根本的な限界があります。
一方で、AI模擬患者が医学教育を変えつつある事実は、大きな希望です。深夜の自室で何度でも問診練習ができる環境は、将来の医師のスキル向上に確実に貢献するでしょう。
AIは最高の勉強仲間です。けれど、まだ信頼できる主治医ではありません。
気になる症状があったとき、AIの回答で安心するのではなく、「AIの情報を持って、かかりつけ医に相談する」。それが、AI時代の賢い医療との付き合い方ではないでしょうか。
本日のまとめ
- AIの臨床推論力の本質: 試験では90%超の正答率でも、実際の臨床を模擬した環境では精度が10分の1以下に急落する。鑑別診断という最も重要なステップが最大の弱点
- AI医療の最も有望な活用法: 「単独の診断者」ではなく「医師のコパイロット」や「医学教育のトレーニングパートナー」としての役割
- 判断に迷ったら: AIの回答はあくまで情報収集の一手段。具体的な症状の診断・治療方針は必ずかかりつけ医に相談してください