はじめに:「AIが医師を超えた」は本当か?
「AI が放射線科医を凌駕した」——そんな見出しを、ここ数年で何度も目にされたのではないでしょうか。
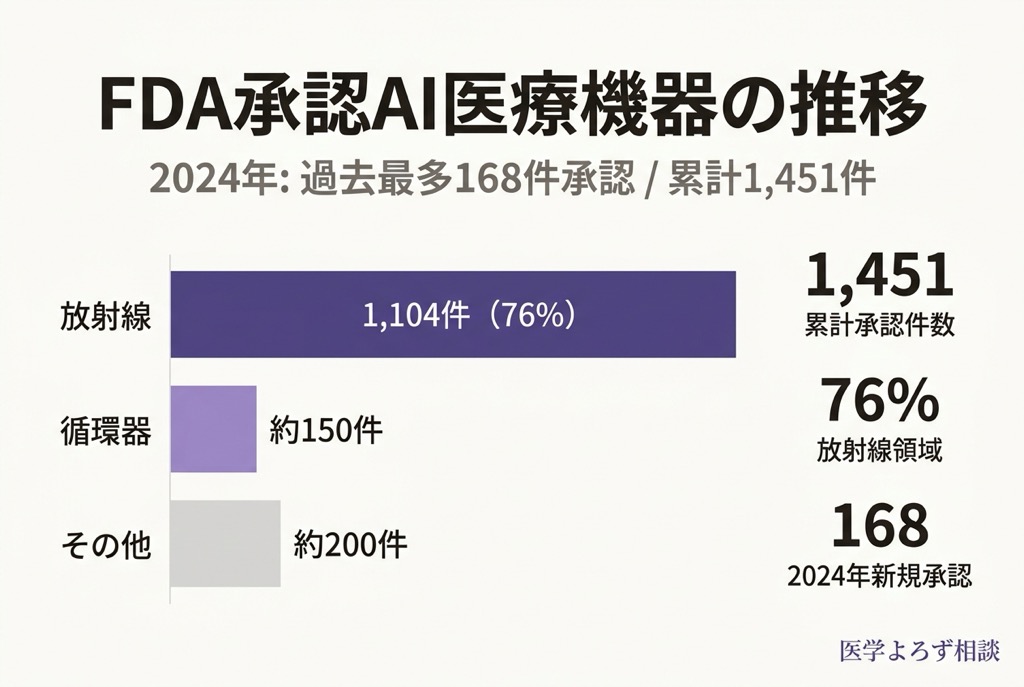
2012 年、深層学習が画像認識コンテストで圧倒的な精度を見せて以来、医療画像診断は AI 応用の最前線であり続けてきました。2024 年だけで FDA が承認した AI 医療機器は過去最多の 168 件。累計 1,451 件のうち、実に 76% が放射線画像領域に集中しています [1]。
しかし、「研究室での精度」と「臨床現場での実力」は同じでしょうか。
2025 年、この問いに初めて大規模ランダム化比較試験(RCT)で回答を出した研究が The Lancet に掲載されました。同時に、生成 AI(ChatGPT 等)の診断能力を 83 研究で検証したメタアナリシスも発表され、「AI vs 医師」の構図はさらに複雑な様相を呈しています。
本記事では、放射線・皮膚科・病理・眼科の各領域における最新のシステマティックレビューとメタアナリシスを横断的にレビューし、AI 画像診断の「本当の実力」と「まだ超えられない壁」を、臨床医の視点から解説します。
AI 画像診断の全体像:1,451 件の承認が意味すること
FDA 承認の爆発的増加
FDA が公開する AI 対応医療機器リストによれば、2024 年の新規承認は 168 件と過去最多を記録しました [1]。累計では 1,451 件に達し、その内訳を見ると医療画像 AI の圧倒的な存在感がわかります。
- 放射線領域: 1,104 件(76%)
- 循環器領域: 第 2 位
- その他(眼科・病理等): 残り
企業別では GE HealthCare(120 件)、Siemens Healthineers(89 件)、Philips(50 件)と大手画像機器メーカーが上位を占める一方、Aidoc(31 件)のような AI 専業企業も急成長しています。
特筆すべきは、2025 年 2 月に Aidoc が取得した ファウンデーションモデルベースの AI 機器としては世界初の FDA 承認です。肋骨骨折トリアージ用で、一つの基盤モデルから複数の臨床タスクに展開できるアプローチは、今後の AI 医療機器開発の方向性を示しています。
日本の規制動向:PMDA と日本医学放射線学会
日本でも AI 医療機器の導入は着実に進んでいます。
PMDA(医薬品医療機器総合機構) は「AIを活用したプログラム医療機器に関する専門部会」を設置し、SaMD(Software as a Medical Device)の承認プロセスを体系化しています [2]。2024 年には日米欧三機関合同で AI 医療機器の承認基準に関する共同ガイダンスが発行され、相互承認の基盤が構築されました。2025 年 4 月には「プログラム医療機器の薬事開発・承認申請に関する手引き」が最終更新され、市販後の変更管理に関する新通知も反映されています。
日本医学放射線学会 は 2025 年 3 月に「人工知能技術を活用した放射線画像診断補助ソフトウェアの臨床使用に関する管理指針(第 2 版)」を公開しました [3]。現在 43 種の AI ソフトウェア が認証を受けており、2024-2025 年度の画像診断管理認証制度ではAI管理指針の遵守が施設認証の条件に組み込まれています。
領域別エビデンス:AI は本当に医師より正確なのか
1. マンモグラフィ:MASAI 試験——世界初の RCT が出した答え
AI 画像診断の有効性を ランダム化比較試験(RCT) で検証した研究は、長らく存在しませんでした。それを変えたのが、スウェーデンで実施された MASAI 試験です [4]。
MASAI(Mammography Screening with Artificial Intelligence)試験
- デザイン: ランダム化比較試験(非劣性・単盲検)
- 対象: 105,934 名の女性(集団検診受診者)
- 介入群: AI 支援読影(Transpara, ScreenPoint Medical)
- 対照群: 標準的なダブルリーディング(AI なし)
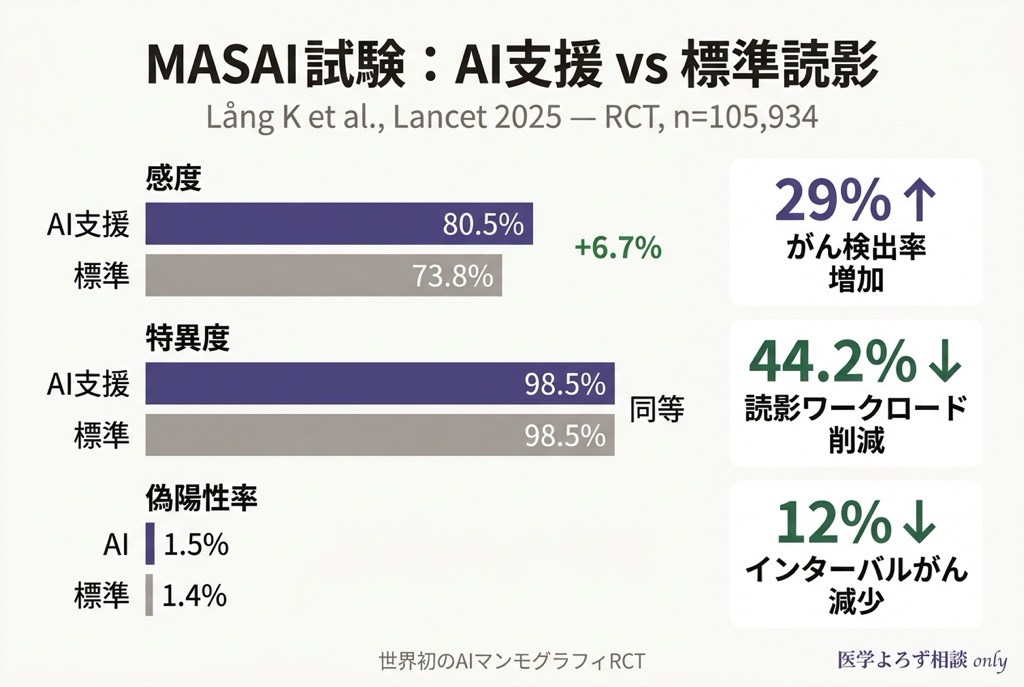
最終結果(2025 年 Lancet 掲載):
| 指標 | AI 支援群 | 標準群 | 差 |
|---|---|---|---|
| 感度 | 80.5% | 73.8% | +6.7% |
| 特異度 | 98.5% | 98.5% | 同等 |
| がん検出率 | 29% 増加 | — | — |
| 偽陽性 | 772 件(1.5%) | 765 件(1.4%) | +7 件 |
| 読影ワークロード | — | — | 44.2% 削減 |
| インターバルがん | — | — | 12% 減少 |
この結果の臨床的意義は極めて大きい。AI 支援により 感度が 6.7 ポイント向上 しながら、特異度は同等に保たれ、偽陽性の増加はわずか 7 件。さらに、読影にかかるワークロードが 44.2% 削減 され、検診後 2 年以内に発見される「インターバルがん」も 12% 減少 しました。
つまり、MASAI 試験は「AI が医師に取って代わる」のではなく、「AI が医師の目を強化し、見逃しを減らし、業務効率を上げる」 という協働モデルの有効性を、世界で初めて RCT レベルのエビデンスで実証したのです。
2. 皮膚科:AI 感度 87% vs 臨床医 80%——ただし「現実」との乖離
皮膚科領域は、AI 画像診断が最も成熟した分野の一つです。
npj Digital Medicine に掲載されたメタアナリシスでは、皮膚がん診断における AI と臨床医のパフォーマンスが直接比較されています [5]。
| 指標 | AI | 臨床医 |
|---|---|---|
| 感度 | 87.0% | 79.8% |
| 特異度 | 77.1% | 73.6% |
数字だけ見れば AI の圧勝です。しかし、ここには重要な但し書きがあります。
多くの研究がレトロスペクティブ(後ろ向き研究) であり、「きれいに撮影された典型的な病変画像」での評価が大半です。実際の臨床では、患者の訴え、病変の触感、分布パターン、既往歴など、画像には映らない情報が診断に大きく寄与します。
さらに興味深いのは、同じグループによる「Human-AI 協働」のメタアナリシスです [6]。AI 単独よりも 医師 + AI の協働 の方が診断精度が向上するケースが多い一方、automation bias(自動化バイアス) ——AI の誤った判断に医師が引きずられてしまう現象——のリスクも報告されています。
これは実臨床への実装において非常に重要な課題です。AI を「ブラックボックス」として盲信するのではなく、AI の出力を批判的に評価する能力が医師に求められます。
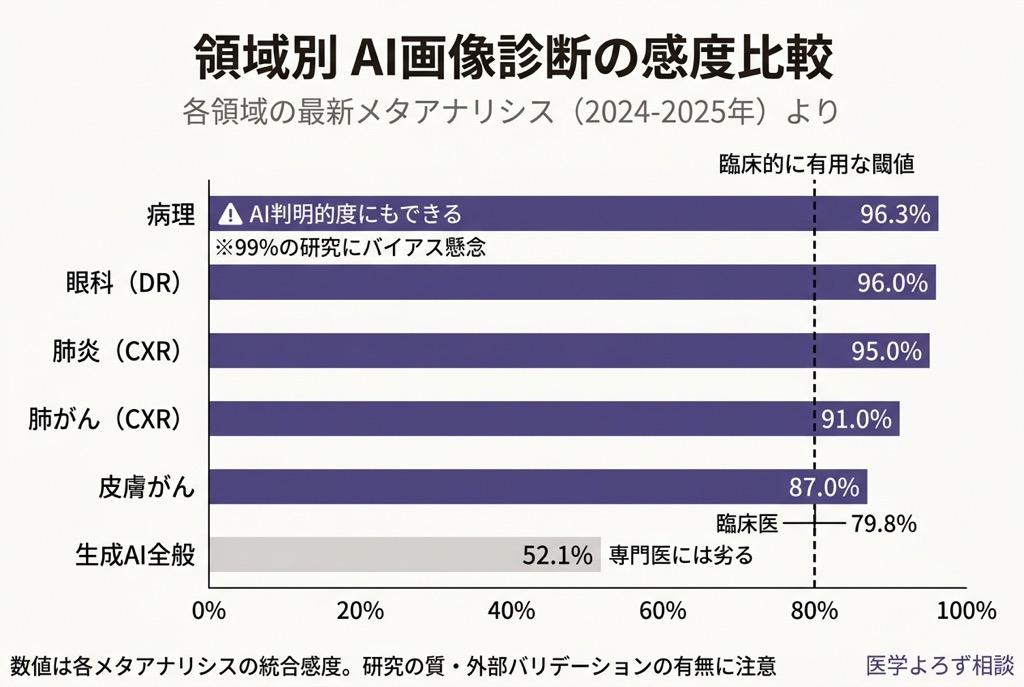
3. 病理診断:感度 96.3%、しかし 99% の研究にバイアス
デジタル病理学における AI のメタアナリシスは、驚異的な数字を示しています [7]。
- 感度: 96.3%
- 特異度: 93.3%
一見すると、AI が病理医を超える日は目前に思えます。しかし、このメタアナリシスが同時に明らかにしたのは、99% の研究にバイアスの懸念がある という事実です。QUADAS-2(診断精度研究の質評価ツール)でほぼ全研究が high risk または unclear と判定されました。
主な問題は以下の通りです:
- 外部バリデーションの不足: 学習データと同じ施設の画像で評価しているケースが大半
- 症例選択バイアス: 典型的で「わかりやすい」症例が偏って含まれる
- 比較対象の不統一: 病理医の経験年数、判定条件がバラバラ
病理 AI の潜在能力は疑いありませんが、「96.3%」という数字をそのまま実臨床に当てはめることはできません。
4. 眼科(糖尿病網膜症):AI スクリーニングの最前線
眼科は、AI が最初に FDA 承認を獲得した 領域です。2018 年の IDx-DR(現 LumineticsCore)は、医師の介在なしに糖尿病網膜症を自律的にスクリーニングする初の AI として承認されました。
2025 年のメタアナリシスでは、規制当局承認済みの深層学習システムの統合的な診断性能が評価されています [8][9]。
- EyeArt システム: 感度 96%、特異度 88%
- AI スクリーニング全体: 手動スクリーニングと同等以上の感度・特異度
眼科 AI が他の領域より実装が進んでいる理由は明確です。眼底画像は 標準化された撮影プロトコル で取得され、判定基準も国際的にコンセンサスがある。つまり、AI が最も得意とする「明確に定義されたタスク、均質なデータ」の条件を満たしているのです。
発展途上国では眼科医が大幅に不足しており、AI スクリーニングによって 数百万人の失明予防 につながる可能性があります。
5. 胸部 X 線:最も研究が多い領域
胸部 X 線は AI 画像診断研究が最も蓄積している領域です [10]。
- AUC(曲線下面積): 0.76〜0.95
- 感度: 85% 以上(多くの研究で)
- 特異度: 68% 以上
- AI + 人間の組合せ: 感度が 2〜9% 向上
疾患別の感度は:
- 肺がん(結節検出): 91%
- 肺炎: 95%
- COVID-19: 75%
結核スクリーニング専用の AI ソフトウェア(qXR, CAD4TB, Lunit INSIGHT CXR 等)については、5,651 文献から 21 研究を採用したメタアナリシスが行われ、WHO 推奨閾値を満たすシステムが同定されています [11]。
気胸検出においても、深層学習モデルは高い診断精度を示しており [12]、Aidoc の気胸トリアージ AI は既に FDA 承認を取得しています。救急で「見逃しが命に直結する」疾患において、AI がトリアージとして機能する実用的なユースケースが確立されつつあります。
生成 AI(ChatGPT 等)の実力:専門医にはまだ及ばない
ここまで紹介した AI は、特定の画像タスクに特化して訓練された 領域特化型 AI です。では、GPT-4 や Claude のような 汎用的な生成 AI(LLM) は、医学診断においてどの程度の実力を持っているのでしょうか。
2025 年に発表された 83 研究のメタアナリシスは、この問いに対する現時点で最も包括的な回答です [13]。
主な知見:
- 生成 AI 全体の診断精度: 52.1%
- 医師全体との比較: 有意差なし
- エキスパート医師との比較: AI が有意に劣る
つまり、汎用 LLM の診断能力は「平均的な医師」レベルにはあるものの、各領域の専門医には明確に及ばない のです。
放射線画像の鑑別診断に限定した別のメタアナリシスでは、さらに興味深い結果が出ています [14]。放射線科医が AI 生成レポートを評価したところ:
- 領域特化モデルの採択率: 70.5%
- GPT-4Vision の採択率: 29.6%
領域特化モデルが汎用 LLM を大幅に上回り、GPT-4Vision のレポートは 73.6% のケースで最低評価でした。
現時点で FDA 承認済みの LLM ベース画像診断 AI はゼロ です。汎用 LLM はあくまで実験的なツールであり、臨床での画像診断に直接使用すべき段階にはありません。
AI が「まだ超えられない壁」:バイアス・汎化・公平性
外部バリデーションの壁
AI の診断精度が「研究室」と「実臨床」で大きく異なることは、複数のシステマティックレビューで明らかになっています。
放射線 AI の汎化性を評価したシステマティックレビュー [15] では:
- 適格研究はわずか 6 件(研究自体が少ない)
- 外部バリデーション 86 研究の中央値症例数は 240 例
- 約半数で外部バリデーション時に性能の微増
- 約 4 分の 1 で大幅な性能低下
- 前向き臨床試験を含む研究はゼロ
「内部バリデーションで AUC 0.95」でも、異なる施設・異なる患者集団・異なる撮影機器で再現できるかは別問題です。
人種・性別バイアスの深刻さ
2024 年に Nature Medicine に掲載された研究は、AI 画像診断のバイアス問題を最も鋭く告発した論文の一つです [16]。
主な知見:
- AI モデルの性能は デモグラフィックショートカットのエンコーディング に依存する
- 人種バイアスを補正すると、新しい集団への汎化能力が低下する
- 胸部 X 線 AI は 黒人患者の疾患を系統的に過少診断 する
これは「精度」と「公平性」のトレードオフという根本的な課題です。学習データの大半が特定の人種・年齢層に偏っている場合、AI はその偏りを増幅する形で学習してしまいます。結果として、AI の導入が 健康格差を拡大 するリスクがあるのです。
日本においても、海外で開発された AI モデルをそのまま導入する際には、日本人集団での検証が不可欠です。体格、骨格、皮膚色、疾患スペクトラムの違いが診断精度に影響する可能性は十分にあります。
Automation Bias:医師が AI に「引きずられる」リスク
先述の皮膚科メタアナリシスで指摘された automation bias は、AI 実装における最大の課題の一つです [6]。
AI が「悪性の可能性が低い」と判定した病変に対して、医師が本来行うべき精密検査をスキップしてしまう。逆に、AI が「悪性の可能性が高い」と過剰に判定したケースで、不要な生検が増える。
AI は医師の意思決定を支援するツールですが、最終的な判断責任は医師 にあります。AI の出力を「参考情報の一つ」として批判的に評価する訓練が、医学教育の中で体系的に行われる必要があります。
科学の現在地:わかっていること、わかっていないこと
確立された知見
- 特定タスクでは AI が人間を超える: 皮膚がん検出(感度 87% vs 80%)、糖尿病網膜症スクリーニング(感度 96%)など、明確に定義されたタスクでは AI が高い精度を示す
- AI + 医師の協働が最善: MASAI 試験に代表されるように、AI が医師の目を補強する協働モデルが最も効果的
- 規制の枠組みは整いつつある: FDA は累計 1,451 件、日本の PMDA/放射線学会も認証制度を整備
- 外部バリデーションで性能が低下することが多い: 研究室の精度を額面通り受け取れない
未解明点・限界
- 前向き臨床試験のエビデンスが極めて不足: MASAI 試験はほぼ唯一の例外
- 人種・性別バイアスの解決策が未確立: 公平性と精度のトレードオフ
- 汎用 LLM の臨床的有用性は未証明: 診断精度 52.1% では臨床応用に程遠い
- 長期的なアウトカム(予後改善・死亡率低下): AI による早期発見が実際に患者の転帰を改善するかの大規模エビデンスはない
- 医療経済学的評価: AI 導入の費用対効果に関するエビデンスが不足
実践ガイド:AI 診断時代に知っておくべきこと
患者として
- AI 支援診断は「セカンドオピニオンの自動化」 と理解する。最終判断は医師が行う
- AI が見逃しを減らす効果は科学的に実証されている(MASAI 試験)
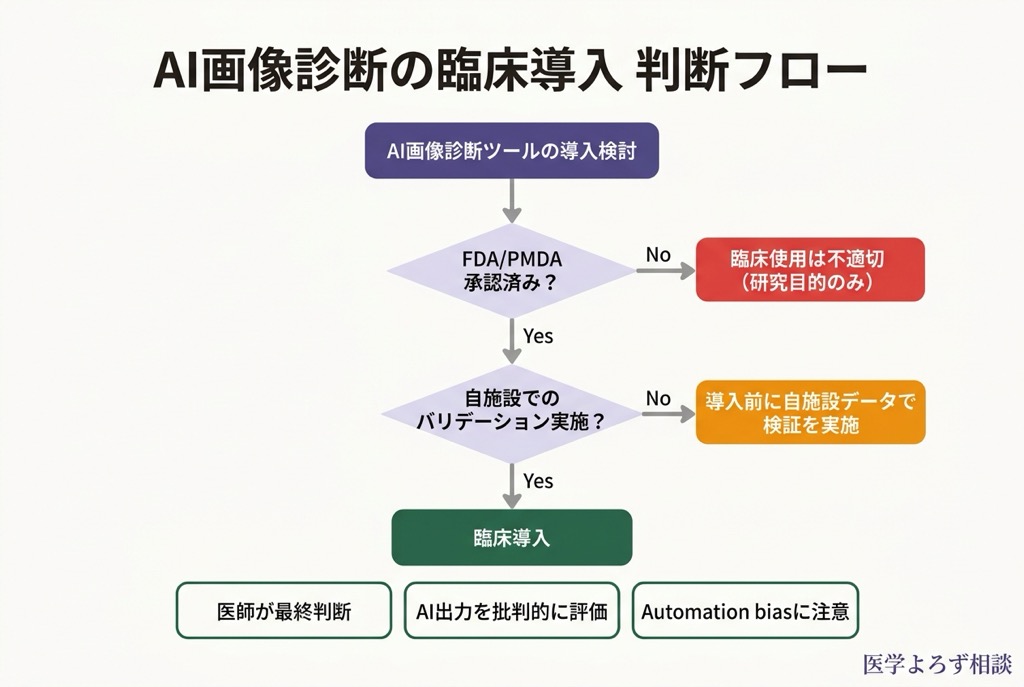
- ただし、すべての AI が同じ品質ではない。規制当局の承認(FDA/PMDA)を得た機器か を確認する
- AI の診断結果に不安がある場合、遠慮なく医師に説明を求めてよい
医療従事者として
- AI は「脅威」ではなく「協働パートナー」。MASAI 試験は読影ワークロード 44% 削減を実証
- automation bias に注意: AI の出力を盲信せず、臨床情報と統合して判断する
- 日本医学放射線学会の AI 管理指針(第 2 版)に基づく施設管理体制の整備が認証要件
- 外部バリデーションのデータがない AI ツールの臨床使用は慎重に
おわりに:AI は医師を「超える」のではなく「強くする」
外来で画像診断の結果を患者さんにお伝えするとき、私たちは画像の所見だけを見ているわけではありません。患者さんの表情、生活背景、ご家族の心配、検査前の経過——これらすべてを統合して、画像の「意味」を解釈しています。
AI は画像のピクセルからパターンを読み取ることにおいて、人間を超える能力を持ちつつあります。しかし、そのパターンが 目の前のこの患者さんにとって何を意味するか を判断するのは、まだ人間の医師にしかできない仕事です。
MASAI 試験が示したのは、AI が医師に「取って代わる」未来ではなく、AI が医師の目を「強くする」未来です。感度が 6.7% 上がり、見逃しが 12% 減り、読影の負担が 44% 軽くなる——その先にあるのは、医師がより多くの時間を「患者と向き合うこと」に使える未来かもしれません。
ただし、バイアスの問題、外部バリデーションの不足、汎用 LLM の限界など、乗り越えるべき壁はまだ多く残されています。AI を正しく理解し、正しく使う——そのためのエビデンスを、これからも一緒に追いかけていきましょう。
本日のまとめ
- AI 画像診断の本質: 特定タスクでは医師に匹敵〜超える精度を示すが、研究の質にばらつきが大きく、外部バリデーションでの性能低下が課題
- 最大のエビデンス: MASAI 試験(RCT, n=105,934)が AI 支援マンモグラフィの有効性を初めて実証。感度+6.7%、ワークロード−44%
- 判断に迷ったら: AI は医師の協働ツールであり、最終判断は臨床医が行う。FDA/PMDA 承認の有無と、自施設での検証データを確認する
関連記事: